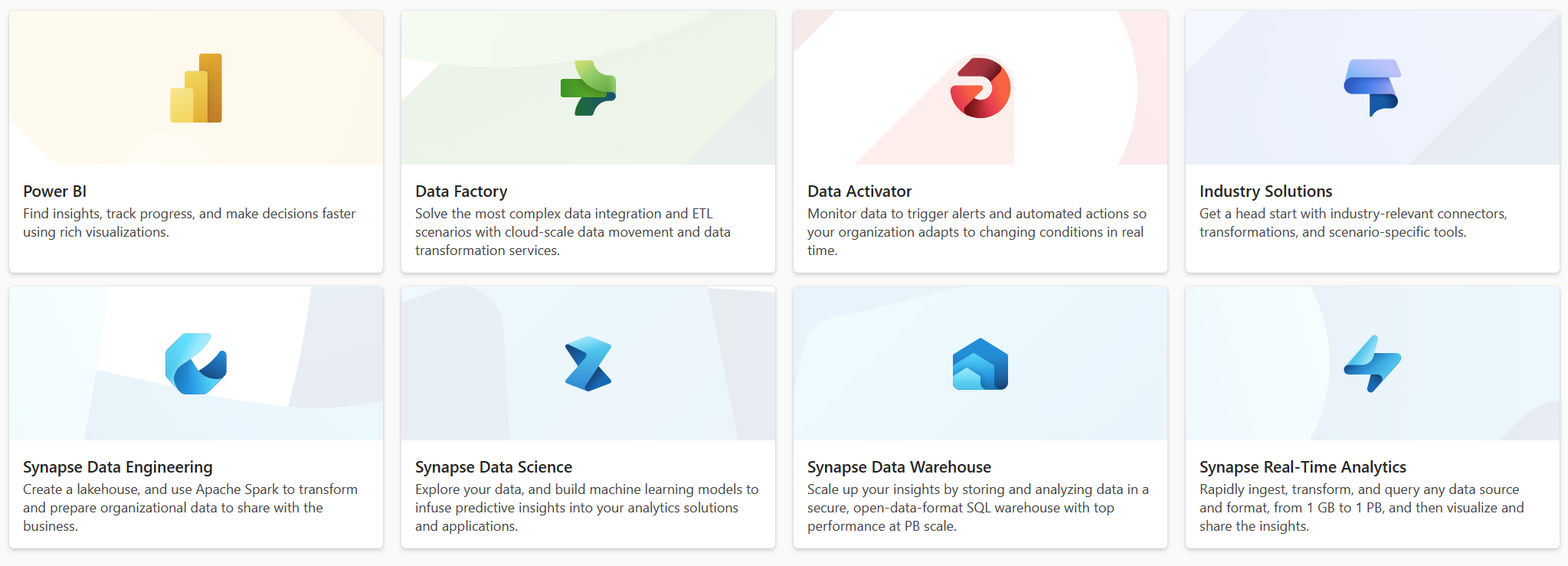
Im ersten Artikel dieser Serie wurden die Stärken von Microsoft Fabric gezeigt. Dieser Beitrag liefert nun einen Überblick über die Kern-Dienste, aus denen Fabric im zusammengesetzt ist. Insgesamt gibt es 8 „User Experiences“, also acht Ansichten, die innerhalb von Fabric aufgerufen werden können. Diese sind maßgeschneidert für die unterschiedlichen Anwender-Profile, die mit Fabric arbeiten, wie z.B. Data Engineers & Scientists, Datenbank-Administratoren oder Business-Analysten. Und so wie es bei diesen Profilen Überschneidungen gibt findet man diese auch in Fabric wieder, beispielweise bei den Data Pipelines die sowohl in Data Factory, Data Engineering und in Data Warehouse eingesetzt werden können.
Data Factory

Mit der Data Factory beginnt in der Regel die Reise ins Fabric-Universum, denn hiermit werden klassische ETL Prozesse abgebildet und die Daten in den OneLake übertragen. Hier stehen zwei Bausteine zur Verfügung: Dataflows und Data Pipelines.
Mit Dataflows lassen sich via Low-code & No-code Konnektoren nahezu beliebig Datenquellen anbinden. Diese werden mit Power Query erstellt und können manuell oder wiederkehrend ausgeführt werden. Beispielsweise lassen sich hiermit stündlich aktuelle Werte aus einer REST API abrufen um später historische Auswertungen tätigen zu können.
Data Pipelines werden benutzt um komplexe Daten-Import-Prozesse zu orchestrieren und deren Ausführung zu planen. Diese Workflows bestehen z.B. aus Python Notebooks, Stored Procedures, Azure Functions oder anderen Dataflows und können dank automatischer Skalierung auch Datenmengen in Petabyte-Größenordnung verarbeiten. Konkret können Data Pipelines z.B. für den initialen Import großer Datenmengen verwendet werden, die vor dem Abspeichern in OneLake gefiltert und anderweitig aufbereitet werden müssen.
Wie die Namen vermuten lassen handelt es sich hierbei um angepasste bzw. integrierte Versionen von Azure Data Factory, Synapse Pipelines und Power BI Dataflows.
Synapse Data Warehouse
In der Synapse Data Warehouse Experience können Warehouses erstellt und verwaltet werden. Hierin werden strukturierte Daten mittels T-SQL gespeichert und abgerufen, wie man es z.B. von einem SQL Server gewohnt ist. Die Daten werden im Delta-Parquet-Format im OneLake gespeichert.
Synapse Data Engineering
In der Synapse Data Engineering Ansicht sind die Lakehouses zu finden. Diese unterscheiden sich von den Warehouses unter anderem dadurch, dass sie sowohl strukturierte (tabellarische) als auch semi-strukturierte (z.B. Websites) und unstrukturierte Daten (z.B. PDF Dateien) enthalten können. Lakehouse nutz im Hintergrund die Apache Spark Engine und kann dementsprechend auch in Spark Jobs verwendet werden.
In welchen Fällen Lakehouses oder Warehouses eingesetzt werden hängt dabei sowohl von den Daten als auch von den Konsumenten (Durchsatz, Spark vs T-SQL) ab.
Synapse Data Science
Synapse Data Science ermöglicht den Zugriff auf alle im OneLake gespeicherten Daten speziell für Data Scientists. Diese können hier ihre Workflows abbilden und aus den angereicherten Daten Erkenntnisse gewinnen. So können z.B. Machine Learning Experimente, Modelle und Notebooks erstellt und ausgeführt werden.
Synapse Real-Time Analytics
Mit Synapse Real-Time Analytics lassen sich mittels Eventstream real-time Events sammeln, verarbeiten und weiterleiten. Eine KQL-Datenbank kann die Daten im OneLake persistieren und so Fabric-weit zugänglich machen. Über KQL-Querysets können Queries geteilt und z.B. Power BI Reports erzeugt werden. Klassische Anwendungsfälle wären hierfür z.B. IoT- oder Sales-Daten.
Power BI
Power BI ist in der Regel das letzte Tool in der Datenverarbeitungs-Kette. Hier werden die gewonnen Erkenntnisse visualisiert und u.a. für Entscheidungsträger zugänglich gemacht. Die Daten stammen dabei natürlich aus dem OneLake und können sowohl historisch aber auch dank der KQL-Datenbank live gestreamt sein.
Data Activator

Mit dem Data Activator lassen sich Live-Daten in Eventstreams und Power BI Reports auf Muster oder Bedingungen überwachen. Die Logik wird hierbei mit dem No-Code-Tool Reflex entwickelt. Werden passende Events gefunden können Aktionen ausgelöst werden, wie das Benachrichtigen des Benutzers oder das Ausführen von Power Automate Workflows.
Industry Solutions
In Industry Solutions liefert stehen Templates für besondere Szenarien bereit. Aktuell können so mittels dieser Bausteine typische Workflows in Fabric für Nachhaltigkeit, Einzelhandel und Gesundheitswesen erstellt und anschließend den eigenen Bedürfnissen angepasst werden.
Zusammenfassung
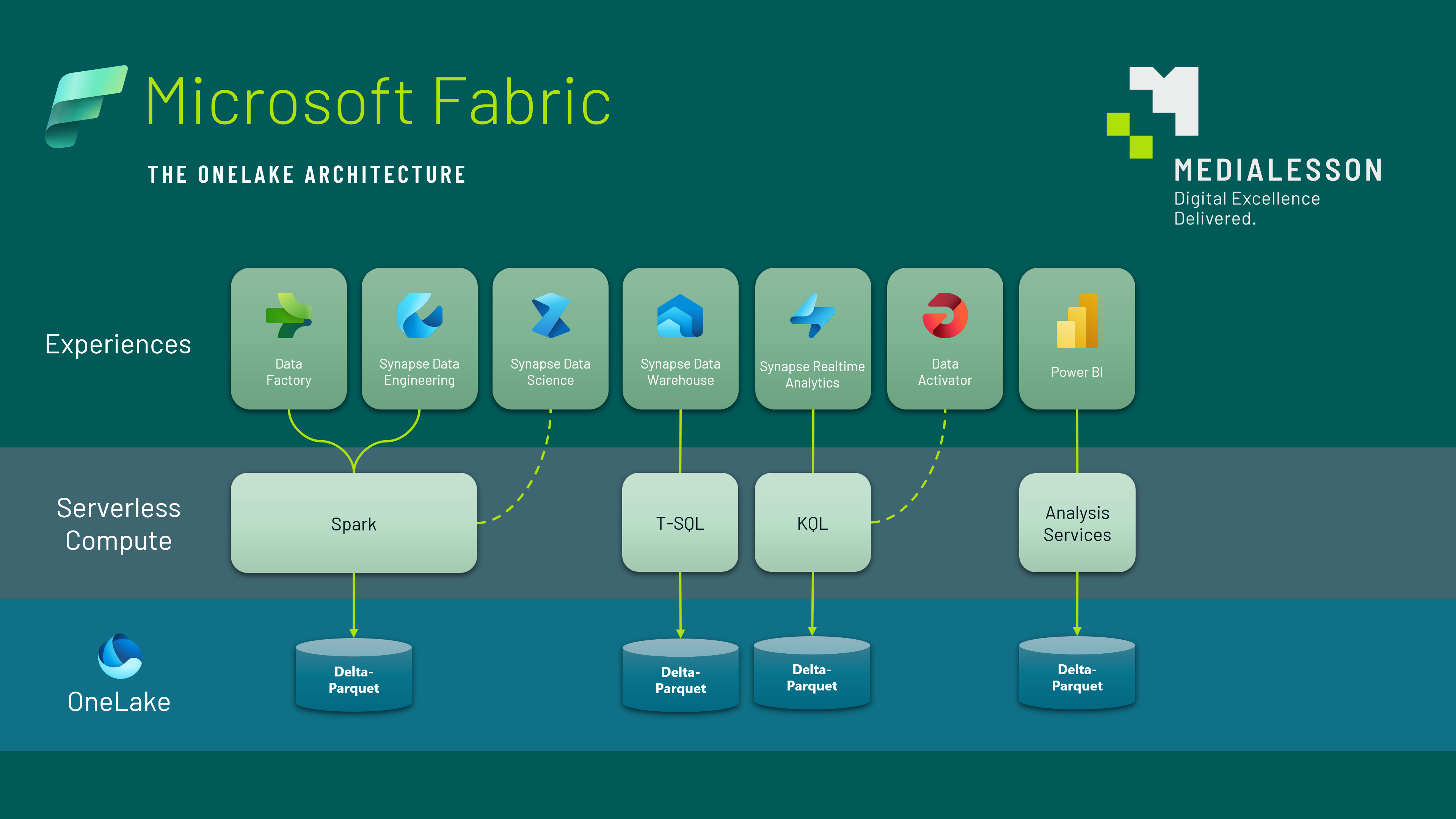
Das nachfolgende Schaubild zeigt noch einmal, wie die Dienste grundsätzlich zueinander in Beziehung stehen. Auch wenn es viele Datenquellen und Formate gibt die auf unterschiedliche Art und Weise verarbeitet werden liegen letztendlich doch alle Information im offenen Apache Delta-Parquet im OneLake.